
用于从网站抓取、提取和下载数据的 Chrome 扩展程序。
3.0.0版本:高级爬虫更新!
这是网络爬虫迄今为止最大的更新!我们彻底重建了引擎,将其从一个简单的抓取工具转变为一个强大、智能的多页面抓取工具。感谢您的反馈!
✨ 新主要功能:
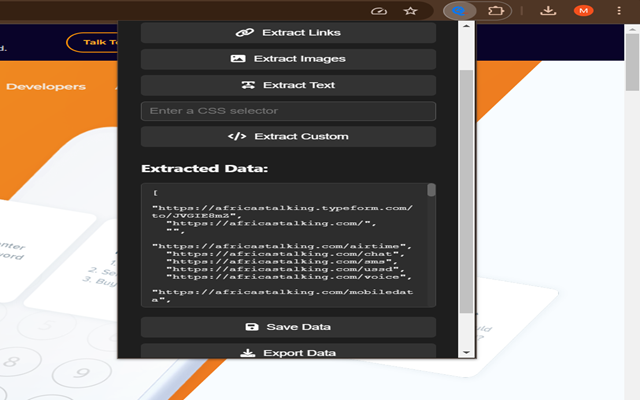
多页面爬行:释放爬虫的真正潜力!您现在可以设置“抓取深度”以自动从一个页面导航到另一个页面,从整个网站(而不仅仅是单个页面)提取数据。
高级数据提取引擎:简单的提取器现在是一个强大而精确的工具。现在,您可以为重复项目(如产品列表或博客文章)定义“容器”,并指定多个“字段”以一次性提取结构化数据(如标题、价格和图像 URL)。
完全爬网控制:您现在可以完全控制爬网过程。新的暂停、恢复和停止按钮使您可以灵活地管理长时间运行的任务。
导出为 CSV:根据大众需求!现在,您可以将提取的数据直接导出到 CSV 文件,以便在 Microsoft Excel 或 Google Sheets 中打开。原始 JSON 导出仍然可用。
🚀 改进和修复:
更智能的抓取:爬虫现在可以智能地检测并忽略“404 Not Found”错误页面中的内容,为您提供更清晰、更相关的数据。
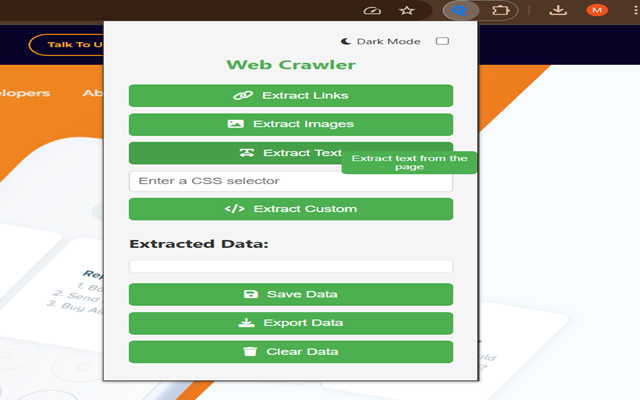
交互式教程:新的“帮助”图标可打开教程,清楚地解释如何使用新的高级数据提取系统,并配有可视化示例。
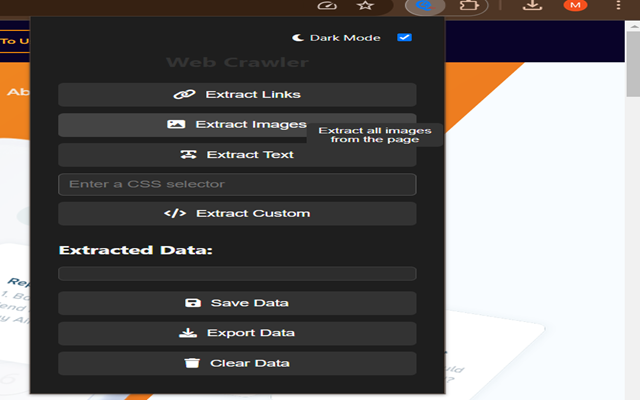
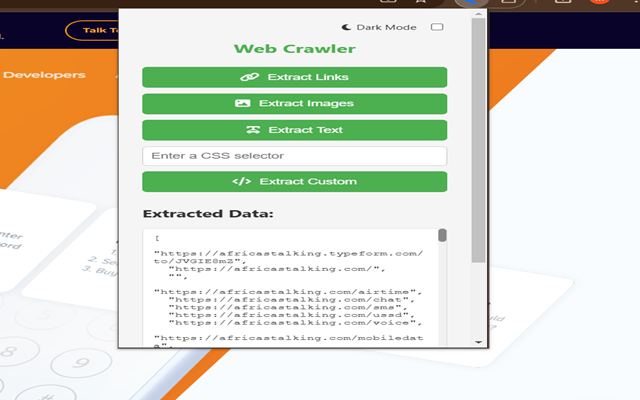
升级的深色模式:深色模式现在比以往更好,并且会在首次启动时自动匹配您的系统主题。您可以随时手动切换它以满足您的喜好。
我们很高兴您能够尝试这些强大的新功能。与往常一样,请使用“发送反馈”按钮让我们知道您的想法或您接下来想看到的内容!