
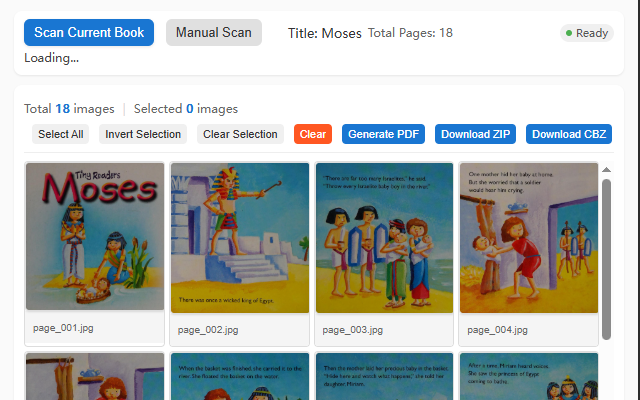
在 Archive.org 书籍页中解析 BookReader 页面,批量下载图片或生成 PDF。
一个功能强大的 Chrome 扩展,用于从 Archive.org 下载书籍页面并生成 PDF、ZIP 或 CBZ 文件。
## ✨ 功能特性
- 🚀 **自动解析**:一键解析 Archive.org 书籍页面,自动获取所有页面信息
- 📥 **批量下载**:支持批量下载书籍图片,自动转换为 JPEG 格式(质量 1.0,最高质量)
- 💾 **本地存储**:使用 IndexedDB 存储图片,支持断点续传
- 📄 **多格式导出**:支持导出为 PDF、ZIP 或 CBZ 格式
- 🎯 **选择性下载**:可以选择特定页面进行下载或导出
- 🖼️ **图片预览**:支持下载前预览图片
- 🔄 **拖拽排序**:支持拖拽调整页面顺序
- 🌍 **多语言支持**:自动适配浏览器语言(中文/英文)
- 🎨 **手动捕获模式**:逐页翻页捕获,适用于需要精确控制的场景
## 🚀 使用方法
### 方法一:自动解析(推荐)
1. **打开书籍页面**
- 访问 Archive.org 书籍详情页,例如:
- `https://archive.org/details/isbn_9780440842897`
2. **启动解析**
- 点击 Chrome 工具栏的扩展图标
- 点击"解析当前书籍"按钮
- 等待自动解析和下载完成
3. **生成文件**
- 解析完成后,选择需要的页面(或全选)
- 点击"生成 PDF"、"下载 ZIP"或"下载 CBZ"按钮
- 选择保存位置,完成下载
### 方法二:手动捕获模式
> ⚠️ **重要提醒**:使用手动捕获前,请务必:
> 1. 在 Archive.org 页面上切换到**单页阅读模式**(点击页面上的单页图标)
> 2. 将书籍翻到**第一页**(起始页)
> 3. 然后再点击"手动解析"按钮
1. **准备阶段**
- 访问 Archive.org 书籍详情页
- 切换到单页阅读模式
- 确保当前显示第一页
2. **开始捕获**
- 点击扩展图标
- 点击"手动解析"按钮
- 扩展将自动逐页翻页并捕获图片
3. **完成下载**
- 捕获完成后,按照方法一的步骤 3 生成文件
### 其他功能
- **图片预览**:点击任意图片可全屏预览
- **选择页面**:使用"全选"、"反选"、"清除选择"按钮
- **删除图片**:选中后点击"删除选中"
- **拖拽排序**:直接拖拽图片调整顺序
- **清空数据**:点击"清空"按钮清除所有本地数据