
Web Data Scraper - 免代码网页抓取。提取数据并导出到CSV、Excel、JSON、Google Sheets 和 Webhook。
在几分钟内,将任何网站转换为结构化、可导出的数据。
Web Data Scraper 是一款高级无代码 Chrome 扩展,专为需要可靠网页数据提取且不想进行复杂设置的专业人士打造。识别重复出现的数据区块,运行高质量提取,并将结果即时导出到 CSV、Excel、JSON、Google Sheets 或 Webhook。
无论你是在构建潜在客户名单、跟踪竞争对手、监控产品目录,还是收集研究数据,Web Data Scraper 都能为你提供从页面到数据集的清晰工作流。
它为何属于高级工具
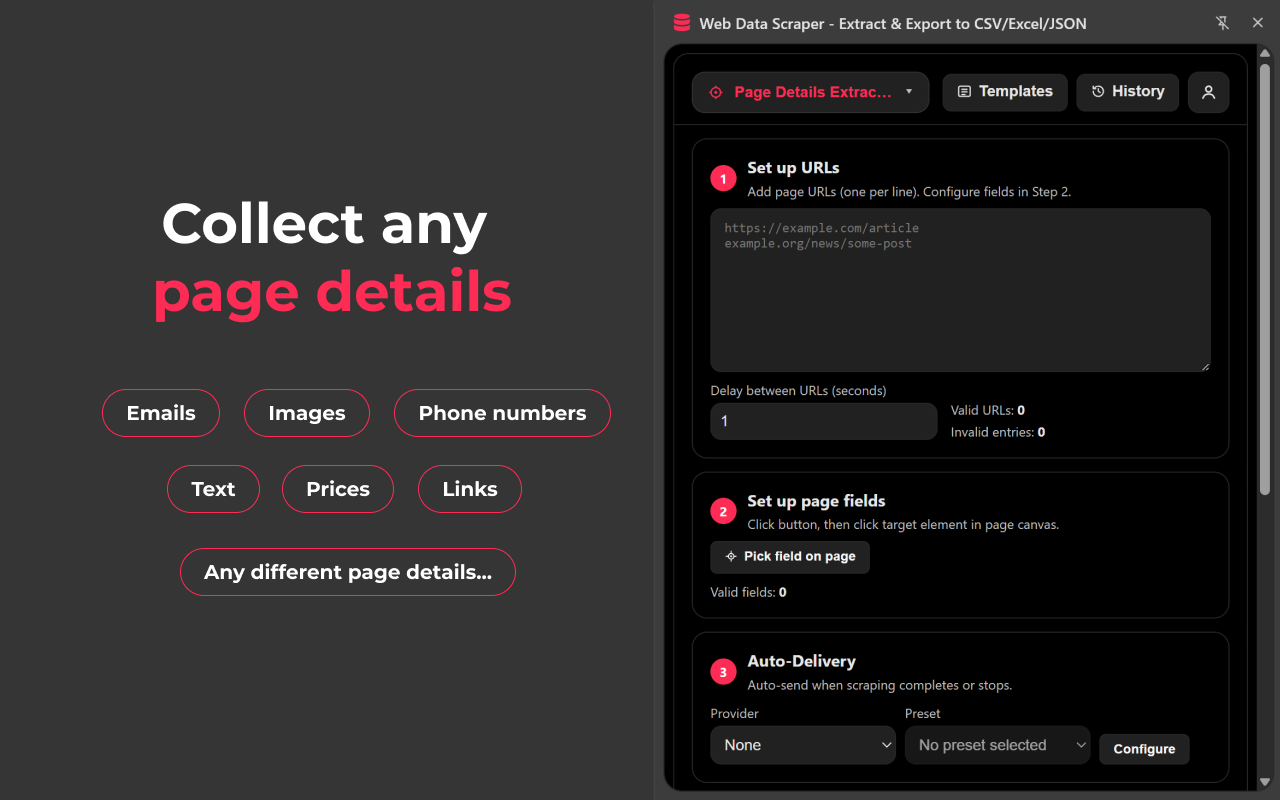
* 快速设置:几次点击即可开始抓取,无需编写代码。
* 可直接投入使用的输出结果:干净的行、可用的列、适合导出的格式。
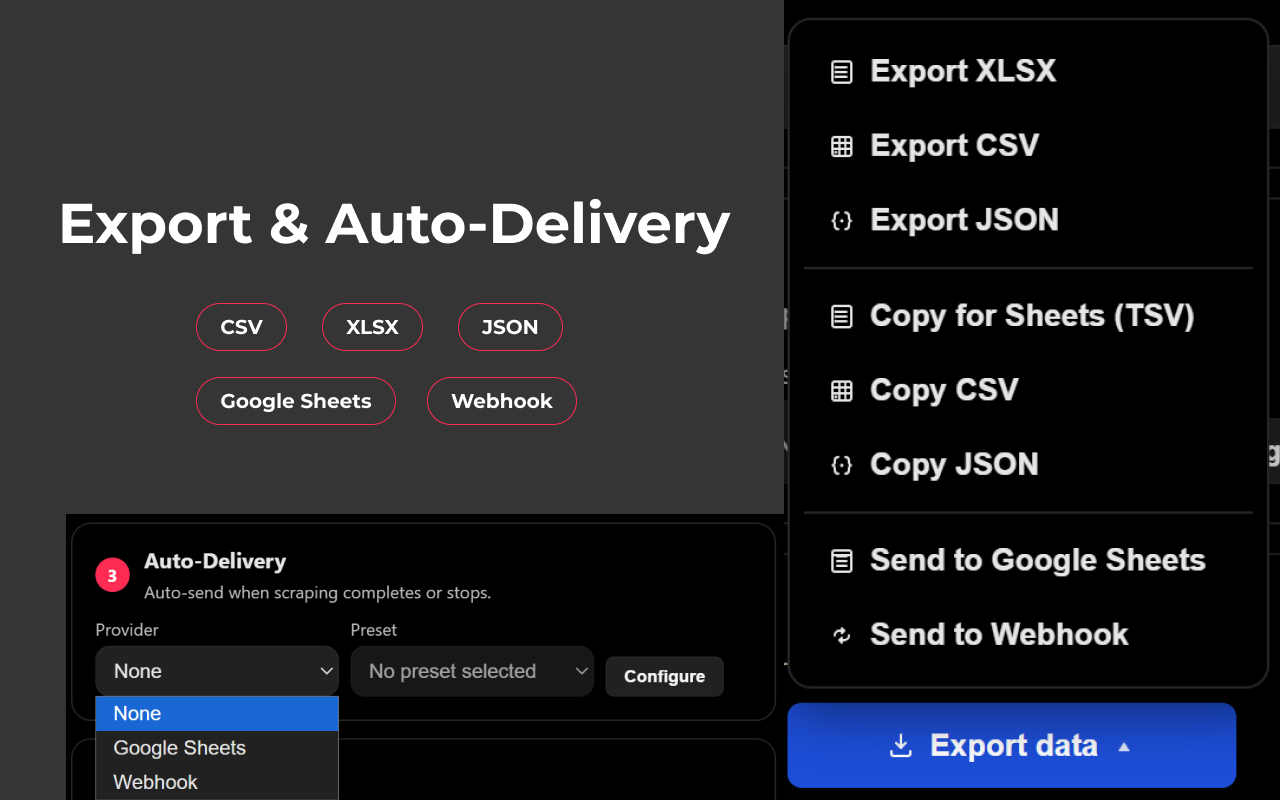
* 灵活的数据交付:一键导出,或在运行完成后自动发送。
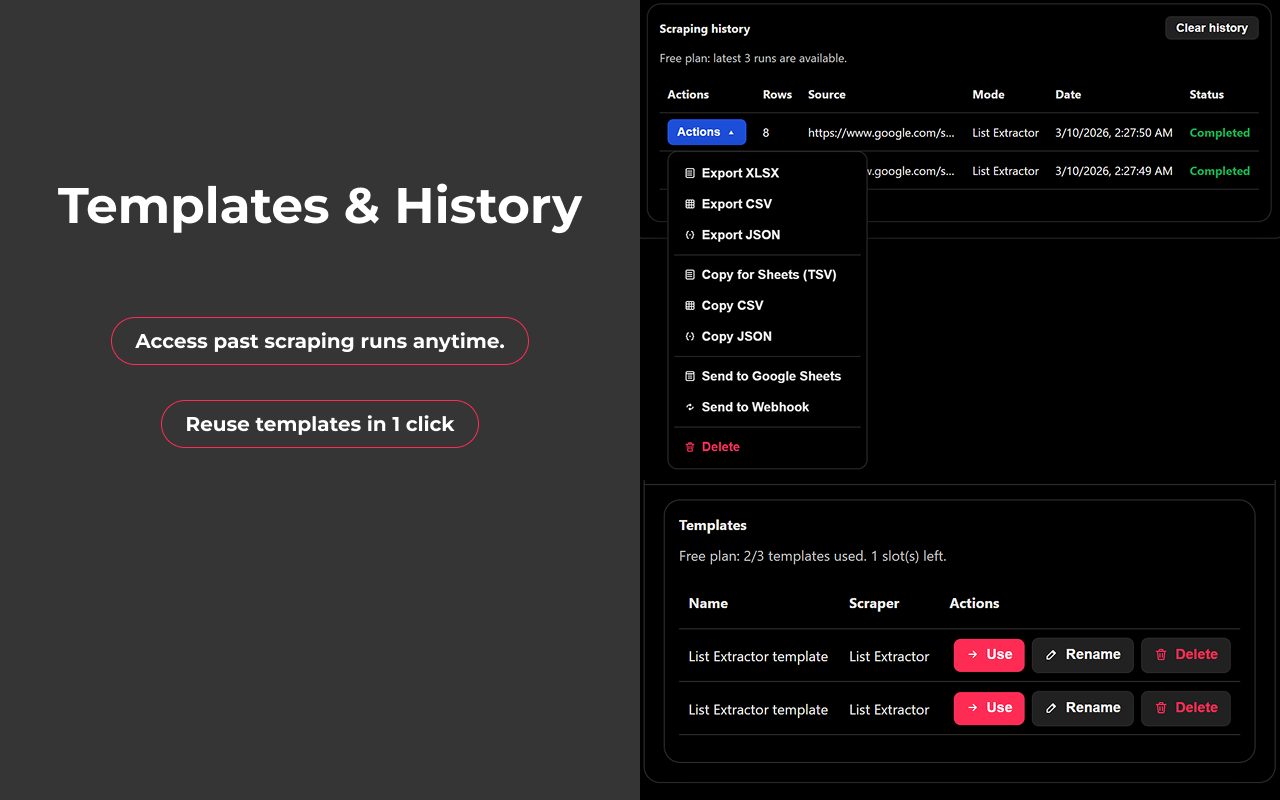
* 可复用的工作流:保存模板,并持续一致地执行重复任务。
* 为规模化而设计:开箱即用支持分页和多页面工作流。
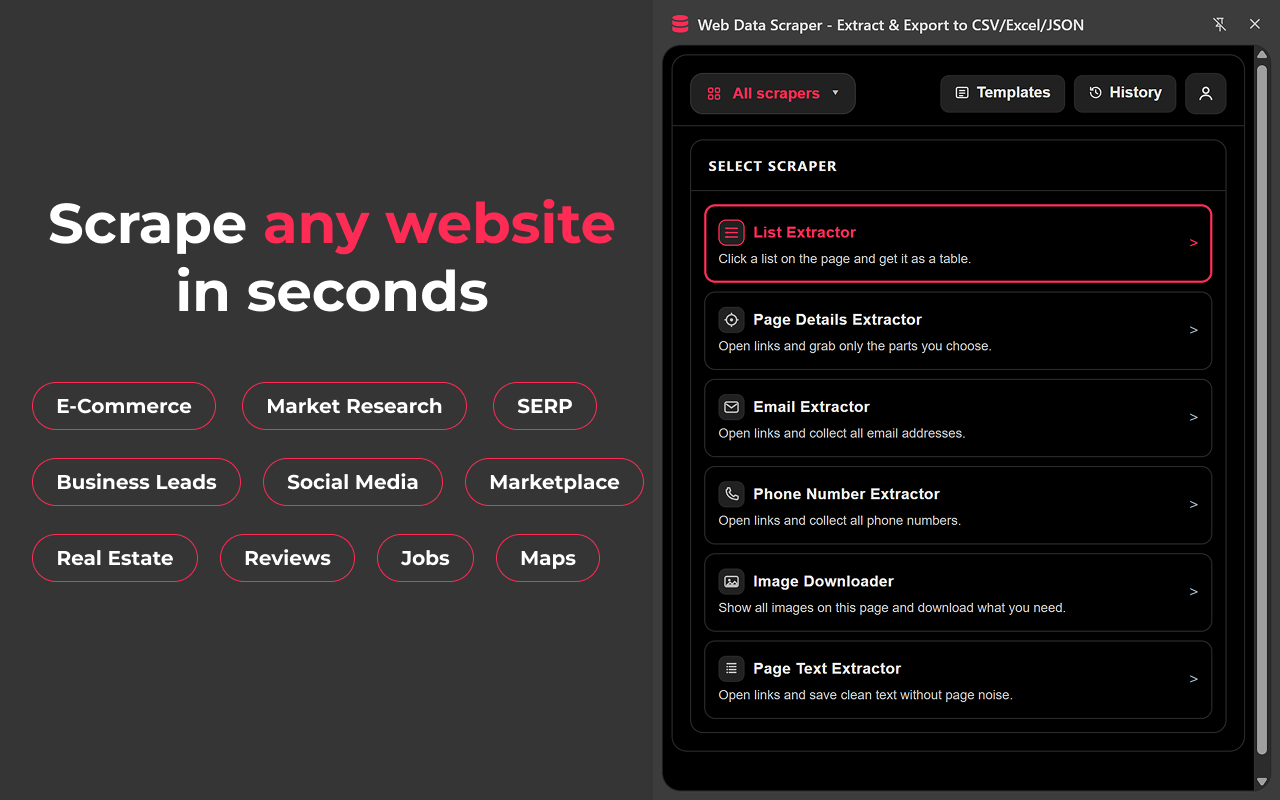
提取模式
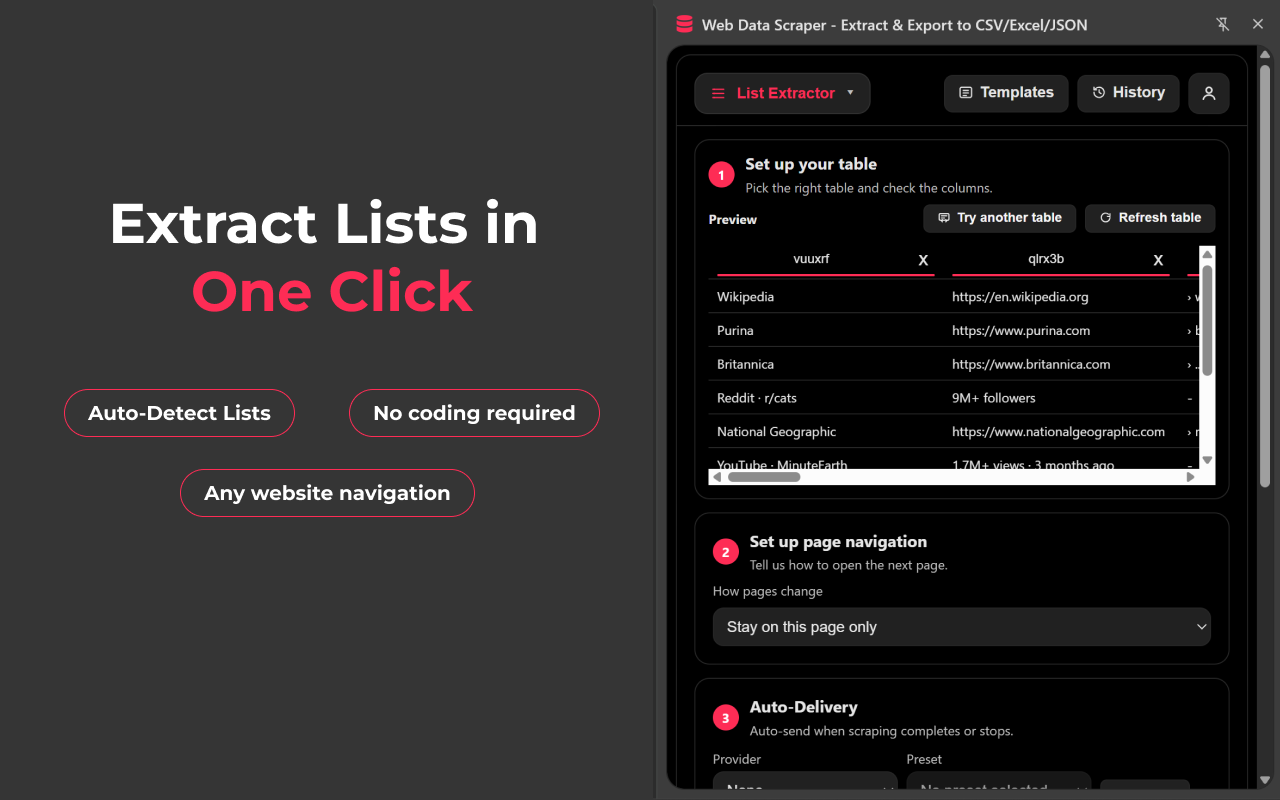
* List Extractor:将卡片、列表和类表格区块提取为结构化行。
* Page Detail Extractor:打开每个 URL,并从详情页抓取所选字段。
* Email Extractor:收集并规范化电子邮箱地址。
* Phone Number Extractor:结合国家上下文收集电话号码。
* Page Text Extractor:提取页面上的有用文本,用于研究和内容工作流。
* Image Downloader:收集并导出页面中的图片资源。
为真实业务场景打造
* 分页选项:Next 按钮、Load More 按钮、URL pattern。
* 支持将数据发送到 Google Sheets,并支持 append 或 upsert-by-key 逻辑。
* 提供可选的行更新控制,带来更安全的同步工作流。
* 通过 Webhook 交付数据,适用于自动化流程。
* 提供历史记录和模板,支持可重复执行的团队流程。
典型使用场景
* 销售与潜在客户开发
* 电商价格/目录监控
* 市场平台和目录网站抓取
* SEO 和 SERP 研究
* 内容情报与市场分析
* 运营报表与数据丰富化
团队为什么选择 Web Data Scraper
* 无代码,但绝不只是玩具级工具。
* 对首次使用者足够简单,对重复性工作流也足够强大。
* 专为减少手动复制粘贴、加快数据处理而打造。
* 直接在数据所在位置工作:你的浏览器中。
工作方式
1. 在 Chrome 中打开目标页面。
2. 选择抓取模式。
3. 预览并验证列。
4. 开始抓取。
5. 立即导出,或自动发送到你的目标位置。
如果你的工作流依赖于快速、可靠地获取结构化网页数据,Web Data Scraper 就是务实且专业的解决方案。