
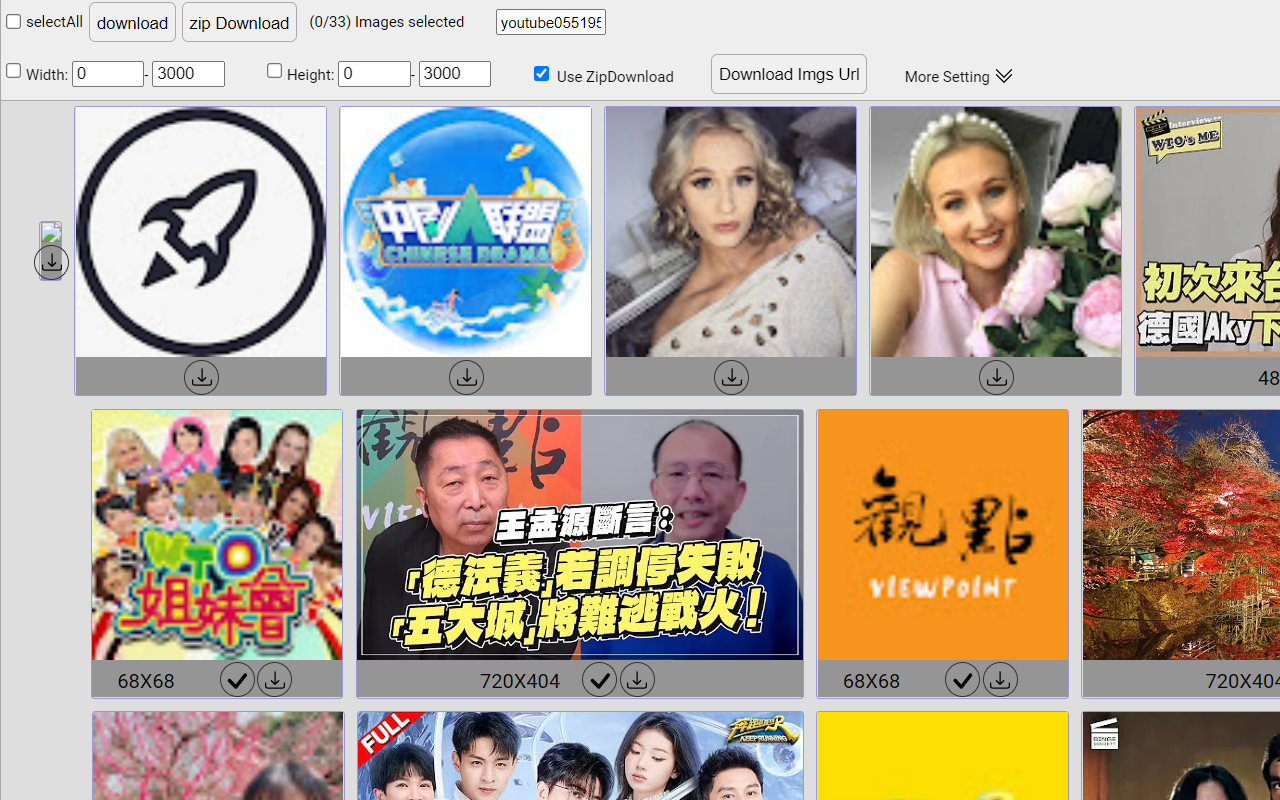
可以从大多数网站提取图像并批量下载。特别是网站右键失效或者图片无法保存
如何使用
基本用法
有两种方式打开脚本页面,
1、快捷键,alt+w,最好用这个方法打开妖七、腾讯漫画、B站等网站。
2.点击弹出按钮
扩展功能
修改下载文件名
脚本会自动生成一个带有域名+时间戳的下载文件名,您也可以手动修改为您需要的文件名。
zip下载
使用zip下载,您可以将所有图片压缩打包成一个zip文件进行下载,这样当您下载多张图片时,只需要下载一个zip包,而不需要为每张图片打开一个下载链接。
现在添加了 zip 下载选项,默认情况下禁用。如果您不使用zip下载,则无需打开此选项。
开启zip选项将需要跨域请求。大多数图片如果不跨域就无法打包成zip包。建议每次更新脚本后允许所有域名跨域,且脚本开源。
自动放大图像
当网站中有多种规格图片时,自动获取大图/原图。获取时,会保留网站显示的原图,同时也会自动获取对应的大图。
手动配置
编写一个txt文件,然后按照以下格式写入规则,然后使用“导入自定义规则”导入
[
{originReg:/(?<=(.+sinaimg\.(?:cn|com)\/))([\w\.]+)(?=(\/.+))/i,替换:" large",tip:"新浪微博"},
]
外面是数组,里面是对象,originReg对应replace函数的一个参数,replacement对应replace函数的第二个参数,tip是提示说明
默认支持自动大图的网站列表
我写在脚本里了,默认支持自动大图的网站列表,也欢迎大家在反馈区留言添加更多自动大图网站
微博、淘宝网(taobao.com、天猫、aliexpss.com、1688.com)、京东、bilibili.com、wallhaven.cc
导出图片地址
导出图片url时最好去掉zip下载选项,否则导出的地址已经转换为base64格式,所以文件会很大。
补充笔记
首先,目前只适合chrome+tampermonkey的组合,edge浏览器使用的chromium内核,我试过几个网站,大部分应该没问题。其他组合很可能会出现问题。由于适配太麻烦,暂时没有计划进行其他组合的适配。
其次,脚本可以在所有网站上运行,但每个网站的策略不同,运行的结果也不同。因此,反馈时需要带上具体的网站,最好是具体的网页
三、漫画下载,我试过B站和腾讯漫画,都很魔性。
笔记:
b站已经可以下载漫画了。 B站漫画有两种阅读模式:
一种是一次加载多个文字,因为一次加载的图片太多,打开脚本后需要异步获取图片。不过下载很爽,只要拖到最后加载所有图片,一次就可以下载几十个字。 (没有拖到最后的时候,会有很多空白的大图,所以如果要下载的话,必须自己手动拖,拖到最后后,打开脚本页面才能下载)。加载慢也是因为B站给图片加了一层画布。下载前需要破解他的画布限制。即使正常的网站图片较多,也不会导致脚本页面的打开速度很慢。
第二个是会显示当前的读数,之前的读数会被销毁,后续的读数不会被pload。在这种阅读模式下,打开剧本和其他网站一样快,但一次只能下载一两页漫画。