
下载祖先 DNA 匹配信息
Ancestry Match Downloader 旨在使用新的 Ancestry DNA API 来扫描、存储和下载您当前的比赛。
该扩展将下载限制为具有 20 厘米或以上共同点的匹配。这是 Ancestry 使用的第四个 Cousin 或 Closer 过滤器。祖先不包括共同匹配中共享距离小于 20 厘米的匹配。
通常,用户最多有 10000 个属于此范围的匹配项。每 5000 场比赛扫描大约需要 1 分钟。普通匹配的扫描仍然需要很长时间才能完成。如果您有 2500 个匹配项,预计 ICW 扫描大约需要 30 分钟。如果您有 4000 场比赛,则预计需要 2 小时。如果您有 6000 场比赛,则预计需要 3 到 4 小时。
更新:
版本0.1.4
更改了导出的默认文件名以包含考生姓名。此外,我还在文件名中包含了 Clusters 的过滤器设置。集群文件名将为 Name-ICW-Clusters-MaxCM-MinCM-Percent-MinSize.XML。
版本0.1.3
添加了导出例程的消息框,以显示导出的匹配数和导出的簇数。
为导出添加了更多错误捕获。
版本0.1.2
在导出例程中添加了一些错误捕获,以捕获匹配数据的不完整扫描。
添加了匹配扫描完成和 ICW 扫描完成时弹出的消息。
添加了如果扫描期间与 Ancestry 服务器的通信中断的警报消息。
版本0.1.1
取消了当前的 ICW 匹配标签。扫描 ICW 匹配时,如果您有亲密的家庭匹配,扫描的 ICW 匹配数量可能需要 15 秒左右才会增加。要有耐心并相信它正在发挥作用。或者使用Ctrl+Shift+I打开开发者工具,点击网络选项卡实时查看网络请求。
将树信息添加到集群输出。匹配名称旁边的列将告诉您是否存在已识别的共同祖先、公共或私有树,以及树中的人数(如果它链接到匹配)。如果没有公共或私有的树,它只会说没有树。
版本0.1.0
清理了用户界面。
添加了一个过滤器以不包含单个匹配集群。将最小簇大小设置为 2 或更大以过滤小簇。
版本0.0.9
修复了一些可能导致损坏的数据保存到存储中的错误。
将扫描匹配信息和树信息合并到单个按钮 pss 中。
早期版本
修复了集群过滤器中的错误。
修复了导致最后几场 ICW 比赛无法保存的错误。
修改了将比赛数据保存到存储中以减少 CPU 负载。
修改了导出 icw 矩阵以减少内存使用。大量匹配导致内存不足崩溃。
更改了扩展名以默认加载到新选项卡中,而不是作为 iframe。如果您更改到新选项卡或窗口,扫描现在会继续。
扫描次数大大减少。
修改了共同匹配下载以消除不需要的请求。这应该会加快 ICW 下载速度。
修复了存储匹配项的共同点时的错误
更新了对 Ancestry API 更新的匹配扫描,将每页返回的匹配项从 20 个增加到 100 个。这大大减少了扫描匹配项和 ICW 匹配项的时间。现在扫描完成速度比以前快 5 倍。
去做:
我正在下载比赛谱系树并将它们组合成一个 gedcom 文件。目前,即使您没有订阅 Ancestry 的服务,Ancestry 测试版也允许查看第 6 代比赛谱系树。
使用说明:
为了使扩展发挥作用,您必须登录您的 Ancestry 帐户,您可以在其中访问 DNA 测试。
我建议在 chrome 中打开一个新窗口,然后浏览到 Ancestry.com。确保您已登录,然后单击扩展图标。该扩展将在新选项卡中加载,并且即使您切换到其他选项卡或窗口也将保持活动状态。
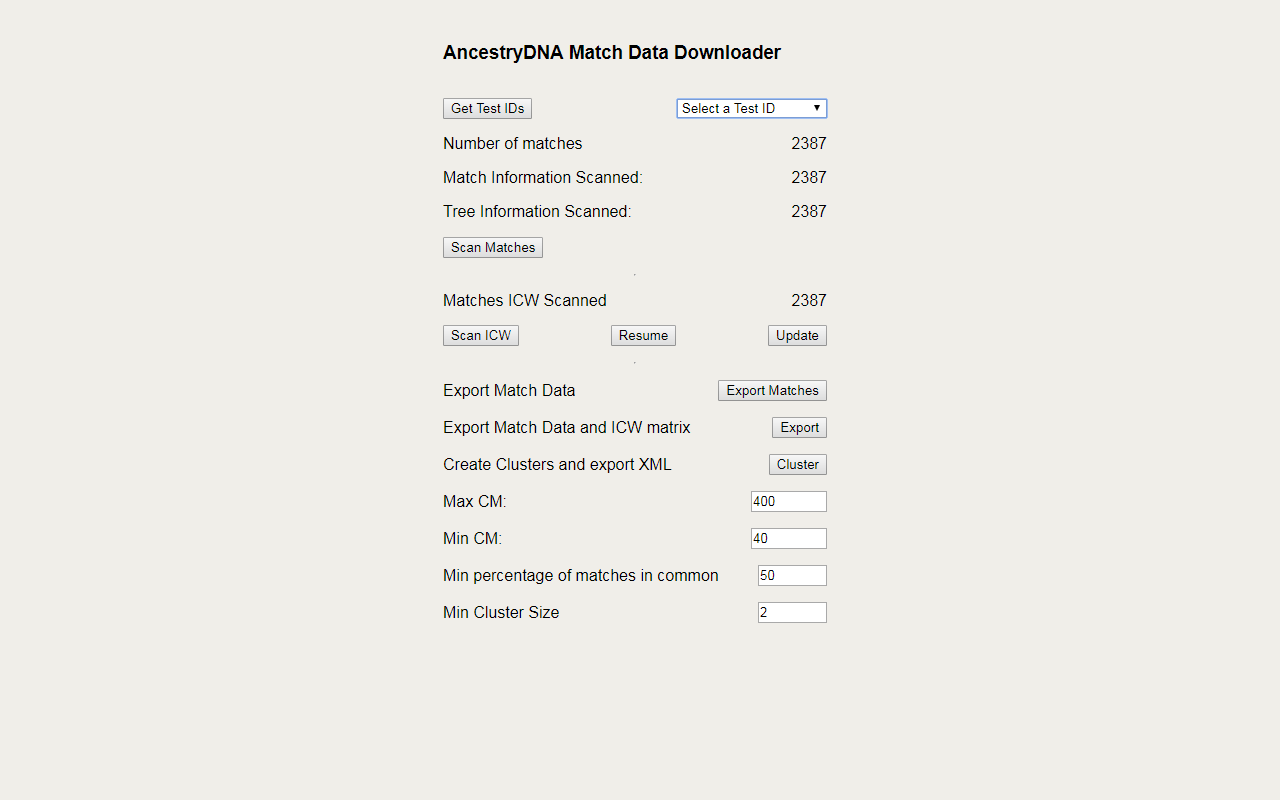
1:首次使用扩展程序时,单击“获取测试 ID”按钮,以在登录帐户上使用可用的 DNA 测试填充下拉列表。 ID 将存储在本地。除非您向帐户添加更多测试人员,否则您只需在第一次运行扩展程序时单击“获取测试 ID”即可。
2:从下拉选择框中选择测试人员的姓名。这将使用当前可用于扫描该测试仪的匹配数量来填充匹配数量字段。
注意:如果您之前扫描过此测试器,它还会填充之前扫描的匹配数、扫描树信息的匹配数以及扫描“共同点”匹配的匹配数。
3:要开始扫描匹配项,请单击“扫描匹配项”按钮。如果您之前扫描过匹配项,则会出现提示,确认您是否希望重新扫描匹配项。 “扫描的比赛信息”将在扫描比赛时更新,并作为进度指示器。扫描完所有匹配项后,它将扫描匹配项以获取树信息。 “已扫描的树木信息”将更新以显示扫描的进度。完成后,匹配信息和树信息编号应与“匹配数量”匹配。
注意:Ancestry 的新 api 不提供仅获取新匹配项的方法,因此每次您希望更新匹配项数据库时,您必须重新扫描所有匹配项。
注意:扫描不会更改比赛的查看状态。它本质上创建了一个与 Ancestry 网站上看到的匹配列表等效的列表。
注意:如果互联网连接丢失或 Ancestry 的服务器在扫描过程中出现问题,并且匹配数与扫描的匹配信息和树信息不同,您将需要通过 pssing scan matches 并从消息框中选择“确定”来重新扫描匹配。
注意:程序将在放弃之前重试扫描 3 次。
4. Matches 与 scan 的共同点是长扫描,但需要使用聚类工具。初始扫描时间将在很大程度上取决于您拥有的匹配项的数量以及这些匹配项的相互关联程度。
注意:如果测试人员有 2000 场比赛,其中每场比赛的平均共同点少于 100 场,则需要 30 分钟才能完成。
注意:如果测试人员有 5000 场比赛,其中每场比赛的平均共同点为 200 场,则需要 3 小时才能完成。
5. 如果普通扫描中的匹配项因某种原因失败(互联网连接失败等),则将保存完全扫描的最后一个匹配项。只要您尚未运行扫描匹配项来更新已扫描匹配项列表,您就可以恢复扫描。单击恢复按钮继续失败的 ICW 匹配扫描。
注意:单击“恢复”将提示您继续失败的扫描。选择“确定”继续。
6. 如果自上次运行“扫描 ICW”后已更新扫描的匹配项,请选择“更新”而不是“恢复”。这将继续扫描您的共同匹配,并将更新先前扫描的与任何新匹配相同的匹配。
7.“导出比赛”按钮将以CSV格式转储当前测试者所有保存的比赛信息。
注意:ICW 匹配 ID 附加在每行匹配的末尾。
注意:标记为 1000 到 1023 的列代表测试人员用来标记其匹配项的任何自定义颜色标签。
注意:如果您有大量匹配项,导出可能最多需要 1 分钟才能完成。
8.“导出”按钮创建 2 个 CSV 文件。第一个包含没有 ICW 数据的比赛信息。第二个是测试者的匹配矩阵,其中 ICW 匹配标记为“X”。
注意:第二个文件 ICW 矩阵可能需要最多 1 分钟才能输出。
9.“聚类”按钮对 ICW 匹配数据运行聚类例程。它根据“最大 CM”和“最小 CM”之间的匹配创建集群。使用“共同匹配的最小百分比”来收紧集群。默认值为 50%,但 65% 或更多可能会产生更好的结果。最大 CM 应设置为低于任何 1C1R 匹配的值以获得最佳结果。最小 CM 将增加或减少簇的数量。将最小簇大小设置为 2 或更大以过滤小簇。
注意:集群的输出是 Excel XML Spadsheet 文件。此格式可以直接在 Excel 2007 或更高版本中打开。
注意:XML 将为每个集群提供 1 个工作表,并且已经对行/列进行了格式化,以便于查看。
注意:该例程计算匹配项作为 ICW 匹配项与集群中的匹配项显示的次数,每列中显示的值就是该匹配项。
注意:匹配项根据该值排序。
注意:我希望在未来的版本中继续研究该算法并改进集群输出。
注意:如果需要 CSV 文件输出,我可以将其添加到输出中。尽管 CSV 不支持多个工作表,但所有簇都必须位于单个工作表上。