
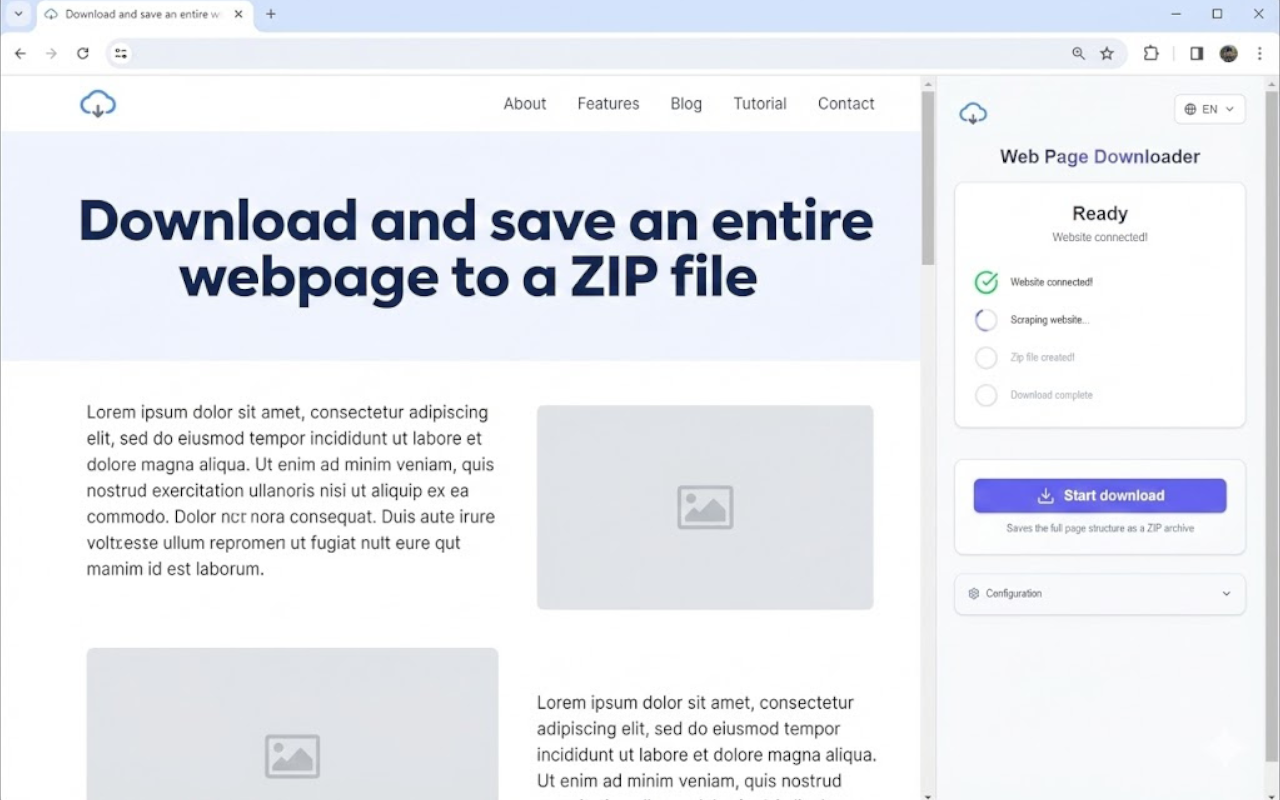

网页下载器允许您下载并保存整个网页(包括链接的资源),以便离线查看。
重要网页内容永不失联。 Web Page Downloader让您保存任何网站的完整、像素级完美副本以供离线查看——无需互联网。
无论网站宕机、更改,还是您只是需要离线访问,此扩展程序都能确保您始终拥有永久存档。
---
主要功能
完整网站存档
保存使网页正常工作的所有内容:
- HTML内容 - 页面结构和文本
- 图像 - 所有照片、图形和背景图像
- 样式表(CSS) - 保留精确的视觉设计
- 脚本(JavaScript) - 保持交互元素功能正常
- 文档 - 自动捕获PDF、DOC和其他嵌入文件
精细下载控制
使用我们灵活的过滤系统精确选择要保存的内容:
- 仅下载图片用于照片库
- 仅保存文本内容,无杂乱
- 获取CSS/JS资源用于开发参考
- 通过排除大型资源创建轻量级存档
企业级性能
专为处理最苛刻的存档任务而构建:
- 流式下载 - 处理数GB网站而无内存问题
- 增量组装 - 处理导致其他工具崩溃的巨大HTML文件
- 智能重试逻辑 - 从网络中断自动恢复
- 队列管理 - 高效并行下载多个资源
值得信赖的隐私和安全
- 100%本地处理 - 所有工作都在您的浏览器中进行,不向服务器发送任何内容
- 无用户跟踪 - 我们不收集分析、浏览历史或个人数据
- 无外部依赖 - 您的数据永不离开您的设备
真正全球化
完全本地化为45种语言,包括:
英语、西班牙语、法语、德语、日语、中文、阿拉伯语、俄语、葡萄牙语、意大利语、韩语、印地语以及33+种其他语言。
---
完美适用于...
研究人员和学生
- 在学术论文和引用消失之前存档
- 保存研究材料以供离线学习
- 创建参考材料的永久备份
旅行者和数字游民
- 下载旅行指南以供离线访问
- 保存地图、行程和预订确认
- 在没有WiFi的航班上阅读文章
Web开发人员和设计师
- 离线检查网站结构
- 提取资源和素材作为参考
- 为作品集或法律目的存档客户网站
记者和内容创作者
- 永久保存证据和来源
- 在文章被编辑或删除之前存档
- 创建离线研究库
数字档案管理员
- 在网站下线之前保存互联网历史
- 创建重要文化或历史内容的备份
- 构建离线知识库
---
额外功能
- 单个HTML文件导出 - 非常适合共享或通过电子邮件发送完整页面
- 纯文本模式 - 提取干净、可读的内容,无格式
- 进度跟踪 - 下载期间的实时状态更新
- 智能资源检测 - 自动查找并保存所有页面依赖项
- 可自定义过滤器 - 保存您的偏好设置以供重复使用
---
使用方法
1. 点击扩展图标 在您想要保存的任何网页上
2. 选择您的选项 - 选择要下载的内容(HTML、图像、CSS等)
3. 点击"开始下载" - 实时观看进度
4. 访问您的存档 - 在下载文件夹中找到ZIP文件或单个HTML文件
就是这样!无需复杂设置、无需账户、无需订阅。
---
注意!某些网站竭尽全力防止任何人下载其内容,因此对于某些网站,下载的HTML可能与原始HTML不同。